The Web’s most common interaction is retrieving HTML pages via requests that are identified with URLs so we can access pieces of information. When we enter a URL on our browser, a request is sent to a server which will work out what sort of response to send back, and most of the time it will be HTML that our browser can parse and display so we can read its contents.
However, web applications can do a lot more today than returning HTML to the browsers, they can allow for instance, products, users and other records to be created, we can update posts on our blogs, upload images and delete our tweets.
To account for this amount of complexity , these requests are not limited to retrieve HTML markup but other formats as well. Furthermore, the request can also trigger actions that make changes to the data stored in the server.
The Representational State Transfer (REST) architecture is widely applied in web application development to help in accessing and changing information related to it. The architecture is defined by a set of components and processes that are outlined by a set of constraints.
This article will cover the bare bones of REST, a few important terms and concepts required to understand it and a few examples of how it might be used in practice.
What is REST?
REST is an architecture style, a set of rules that can be applied when creating web services. Its purpose is to define a uniform way of accessing and modifying web resources.
Information that the browser can request is organised in entities (users, carts, posts, pages), each of these returns specific information which can be accessed via URLS.
Requesting information via a URL, or in other words access a resource, can return the information in multiple formats, or commonly referred to as representations.
With each request, the information includes all data required to make subsequent requests to the server without needing it to know about the whole picture of what is happening in the application (also referred to as state) on the browser side. It also tells us what other resources are available and which can be accessed next so we can keep using the application without having to resort to documentation.
Applying the concept of entities and resources as a way to organize, access and modify information has proven to be a useful approach to when developing applications and often seen as an alternative to other methods such as the Simple Object Access Protocol (SOAP).
This summarizes what REST is at a higher level but the architecture itself is composed of several components and constraints, each with a role to help define how a service designed with REST should work. We can now go into a bit more detail on these constraints and see how they relate with the concepts introduced in this section.
HTTP enables the exchange of information
The interactions with these resources occur through the use of the Internet’s Hypertext Transfer Protocol (HTTP). Since it’s an integral part of working with REST, it is important to understand a few parts of HTTP before moving on, let’s start by defining the request response cycle:
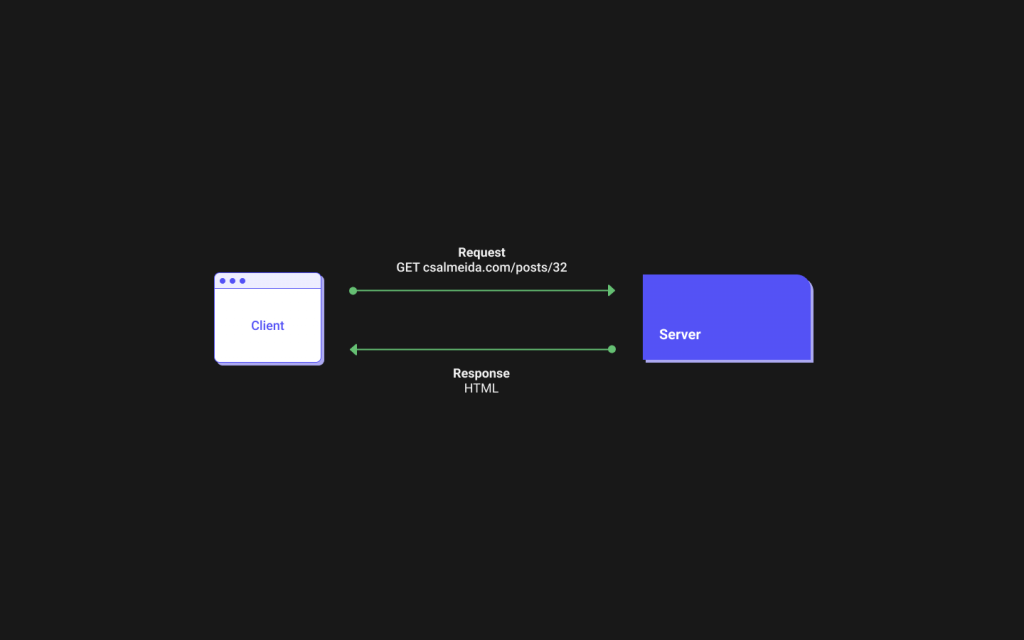
The client (also known as user agent and could be a browser, a terminal or other software) initiates a request to the server using an URL.
The server then works out which type of request this is by reading it carefully. One of the details we should be aware of is the HTTP method used to make the request. Here’s the ones most commonly used in REST:
GET
Retrieves a representation of a resource. These requests should only retrieve data, without changing the resource at all (no side-effects). e.g Show a list of articles.
POST
This type of request submits information to the server which can cause changes to be made, effectively changing the state of the application. e.g Publish a new article or change the email of an existing user.
DELETE
It’s meant to indicate that the resource should be deleted. e.g Clear a shop cart, remove a user from the system.
These methods allow us and the server to understand what action is to be taken with a resource.
A resource is composed of an entity defined as a noun (e.g posts) and can be accessed as a collection or as an instance. Let’s say we would like to retrieve all posts, we could access a resource that could look like csalmeida.com/posts to request them and get an array posts (a collection) to display on a page for example. How about a specific post (an instance)? In that case the URL could look like csalmeida.com/posts/1. The difference here is that an ID is added to the URL to identify the post we would like to access, the server will make use of it to work out which post to get back to the client.
For example, presuming that we are accessing the URL csalmeida.com/users. The /users part of the URL would be the resource we are trying to get to and when a request gets to the server it will process this request, run any code needed to put a response together and retrieve an HTML page listing a set of users.
The reason we would know some information is being accessed instead of manipulated is by looking at the HTTP method used in the request which in this example is a GET request. The HTTP method used can give us some clues as to what a request intends to do but in reality we don’t know what sort of response we are going to get when the browser tries to access a resource.
Looking at the URL, we might assume it returns a page listing all users on the site, but the server could actually return a completely different kind of information depending on what code runs when this request is made. This means that we cannot assume that because a resource (an URL) is described a certain way that we will get what we expect.
There’s also another aspect that we don’t know about which is the kind of response. Although most of the time it is HTML, it could be other formats such as JSON, XML, plain text and more.
These aspects mentioned in the example are relevant because they help describing some characteristics of REST. Now let’s look at each of the major constraints of the architecture.
The REST Constraints
The set of constraints that define the REST architecture is worth knowing about to understand how to apply it when creating web services based on it.
Uniform Interface
It’s the idea that implementations are separate from the services they provide to promote independent system evolution. For example, the same API could be used by a website and a mobile application at the same time, but these elements could evolve independently. Fielding’s points out that the disadvantage of this approach is that information is accessible in a standardized format instead of it being designed for each context.
To achieve this REST takes a resource based approach to that are identified in requests. For example to access the articles of a site a resource could be /articles and to see the list of available the trains timetables another resource could be /timetables.
The manipulation of resources through representations should be possible. This means that a representation (for instance an HTML document should include all the the data and URLS necessary to perform subsequent actions if available. The actions could include, reading a related document or removing an article. For example, accessing csalmeida.com/articles returns an HTML representation of all the articles available on the site. There’s also a “remove article” link that points to csalmeida/articles/32. This link allows us to remove a specific article with all the information the server needs to perform the action.
This ties with the with the concept of having Hypermedia as the Engine of Application State (HATEOAS) which essentially means that each representation includes everything that is necessary for the user to perform subsequent actions in the application either to navigate to another resource or to makes changes to one. In fact, RESTful API expert Les Hazlewood argues that REST boils down to links and state transitions.
Finally there’s the concept of self-descriptive messages which means that each request itself should include enough information for the server to understand and process it.
Stateless
This concept essentially means that the server should not hold any application state for the current user session. The client holds all the state which means that each request made has the necessary information for the server to handle it.
This helps reducing complexity and resources used by the server since it doesn’t have to track the state of the application for each user, all of it is made available on the user side instead.
Cacheable
Essentially the idea of including metadata that specified whether the information returned but the request is cacheable or not and if so, for how long. If the client has already retrieved a representation of something it will cache it and used the next time its requested instead of asking the server for it again. However, this can lead to stale data or in other words, the cached representation the user is seeing might be out of date when compared with what’s available on the server.
Client-Server
The REST architecture bases itself on a client-server setup. The server holds the data and provides resources to the client. The client on the on the other hand requests theses resources once processed by the server. This creates a separation of concerns where the server handles the data storage and leaves business logic unknown to the client. The client hold the application state for that session and the server is unaware of what that looks like on each request it just provides information and executes actions as the client requests, depending on what actions are available and what the client is permitted to do.
Layered System
This concept defines that an applications might have multiple layers where each layer is only aware of it’s immediate layer, or in other words, the one it needs to interact with. Additionally the client should not be able to tell which one is connecting to along the way.
For example the API could be deployed on server A, and the data stored on server B and requests being authenticated in server C. A request is handled by server A, authenticated by server C and the data is then retrieved by server B, the client only gets it’s requested representation back without ever being aware that this has happened.
Code on demand
An optional aspect of REST, it means that in some cases servers might provide code for the client to execute instead of a representation. This could be for instance a CSS stylesheet of Javascript files.
This summarizes the six constrains that define REST, in summary each constrains encourages a separation of concerns when designing a web service.
A practical example of using a REST API
As most RESTful API’s return JSON we’ll make use of the jsonplaceholder API. This API returns example data out of the box without requiring further steps, let’s try the following URL in the browser:
https://jsonplaceholder.typicode.com/postsThe browser will show a JSON representation of the information we’ve requested, it should look similar to this:
[
{
"userId": 1,
"id": 1,
"title": "sunt aut facere repellat provident occaecati excepturi optio reprehenderit",
"body": "quia et suscipit\nsuscipit recusandae consequuntur expedita et cum\nreprehenderit molestiae ut ut quas totam\nnostrum rerum est autem sunt rem eveniet architecto"
},
{
"userId": 1,
"id": 2,
"title": "qui est esse",
"body": "est rerum tempore vitae\nsequi sint nihil reprehenderit dolor beatae ea dolores neque\nfugiat blanditiis voluptate porro vel nihil molestiae ut reiciendis\nqui aperiam non debitis possimus qui neque nisi nulla"
},
{
"userId": 1,
"id": 3,
"title": "ea molestias quasi exercitationem repellat qui ipsa sit aut",
"body": "et iusto sed quo iure\nvoluptatem occaecati omnis eligendi aut ad\nvoluptatem doloribus vel accusantium quis pariatur\nmolestiae porro eius odio et labore et velit aut"
},
// ...
]Each post includes a set of properties, an id, title, body and the author’s ID as userId. Next, let’s access the comments for a post:
https://jsonplaceholder.typicode.com/posts/1/commentsThis resource retrieves all comments associated with the post with ID 1:
[
{
"postId": 1,
"id": 1,
"name": "id labore ex et quam laborum",
"email": "Eliseo@gardner.biz",
"body": "laudantium enim quasi est quidem magnam voluptate ipsam eos\ntempora quo necessitatibus\ndolor quam autem quasi\nreiciendis et nam sapiente accusantium"
},
{
"postId": 1,
"id": 2,
"name": "quo vero reiciendis velit similique earum",
"email": "Jayne_Kuhic@sydney.com",
"body": "est natus enim nihil est dolore omnis voluptatem numquam\net omnis occaecati quod ullam at\nvoluptatem error expedita pariatur\nnihil sint nostrum voluptatem reiciendis et"
},
//...
]We can also observe that this API does not adhere to all the constraints, for example, when we retrieved all posts it didn’t provide further available resources to access the comments or the author’s information, which can leave the user or the developer to guess or rely on documentation to understand what other actions are available on that resource.
A way to make it clearer would be to add the paths or even the full URLs to the response as a way to facilitate access of those other resources if needed:
{
"userId": 1,
"id": 1,
"title": "sunt aut facere repellat provident occaecati excepturi optio reprehenderit",
"body": "quia et suscipit\nsuscipit recusandae consequuntur expedita et cum\nreprehenderit molestiae ut ut quas totam\nnostrum rerum est autem sunt rem eveniet architecto",
"links": [
"https://jsonplaceholder.typicode.com/posts/1/comments",
"https://jsonplaceholder.typicode.com/posts?userId=1"
]
}When requesting each resource we are making an HTTP request which makes has a method specified. The method we’ve been using for out requests is GET. However, how do we know which request is being used?
For that we can inspect networks requests using the browser’s Dev Tools. Each browser is slightly different but it should have a Network tab where the request made and it’s properties can be inspected in a bit more detail:

This concludes this example but there’s a lot more to explore, different HTTP methods and some API’s may only let a resource be accessed if they pass authentication, try to explore all of these on your own by interacting with the Twitter API for example.
Further observations and considerations
The resources can have dynamically generated responses
This means that the contents of a response can change with each request. For example, on an initial request to csalmeida.com/users, might show a page with three users, however a subsequent request can show two if one if them was removed since.
The format of a response can vary
It’s worth keeping in mind that responses can return information on an array of formats. It could be HTML for the browser to parse or a JSON data object to be consumed somewhere else. The same information can be represented in multiple ways.
A resource is a way to access some information and is identified by an URL used for the server to understand how to respond. The response can be any format, also called a representation such as HTML, JPEG image, JSON, XML and more.
Only the client knows what’s up
The state of the application is stored entirely by the user agent (typically a browser) and each request to the server is sent without the server being aware of what other requests occurred before.
This means that a request must include all the information it needs to perform an action in isolation, whether it’s creating, modifying or accessing a resource.
Understanding an already existing API
When accessing a RESTful API the interaction should be similar to other ones you have interacted with. There are collections and it’s individual instances.
This being said, one step that needs to be often taken is getting to know the database schema. What tables are there? Which columns each table includes and how do they relate to each other?
HTTP has its limitations
Martin Nally points out that HTTP is good for performing Create, Read, Update Delete (CRUD) operations but doesn’t take care of querying or versioning which poses a challenge in designing quality APIs. These topics are something worth exploring as well.
No agreement on format of JSON representations
JavaScript Object Notation is a format that’s commonly provided by a REST API. Despite its popularity, there’s no standardized specification on how this data should be structured which could lead to representations being dramatically different between APIs.
A few experts have developed their own solutions by defining specs that are in tune with their needs and respect the REST architecture, here’s a few:
Not all APIs that call themselves RESTful actually apply the REST architecture as intended
There are a lot of APIs that base themselves in the REST achitecture but violate one or more constraints. In this case, these are not considered truly restful and that’s completely fine but it’s worth mentioning since many APIs available for use that follow some of the rules of REST might not actually adhere to others.
Why is it worth knowing about REST?
The use of the REST architecture or modified versions of it (RESTful APIS) are widely used across many applications today. Frameworks such as Laravel, Ruby on Rails and Sails make use of it and abstract a lot of the complexity it has so developers can make use of it to streamline the development process and increase project maintainability.
One other emerging pattern that has seen increased used to design APIs is GraphQL which allows to get access to many resources in a single request. This approach tries to solve the limitations REST presents when it’s needed to quickly adapt to requirements on the client-side.