When I started using Zig a few projects I wanted to build required secrets and configuration to be set, either database details, API tokes or others and it made me think that perhaps a .env would be a good way to load these values into programs.
This required some secrets and configuration to be set in order to run which made me think that perhaps a .env would be a good way to load these values into programs.
Without a separate configuration file I would have to resort to hardcoded values, potentially exposing them in version tracking and to change them it would require to compile a new version of the executable.
Additionally, I thought it would be a great way to learn more about Zig whilst building a project I could use and work on a small challenge, because .env files are incredibly simple (so I thought).
I ended up building Envo, a .env parser for Zig. It reads environment files and makes the values accessible via a Hash Map.
The principle of separating config from code emerged around 2011 with Wiggins’s Twelve-Factor App; the
.envfile as a concrete expression of it came a year or two later, through the dotenv libraries.
I could use an existing project or snippet, there are plenty available:
- https://nofmal.github.io/zig-with-example/environment-variables/
- https://github.com/Niek-HM/zig-config
- https://github.com/dolow/zigenv
- https://github.com/velikoss/dotenv-zig
However, there’s a few reasons I decided to write my own instead:
- Practice architecting and finding a solution for a problem I have never solved before and learn about parsing.
- Better understand how much effort does it take to write your own software, from the ground up.
- Zig is not at
1.0and the language changes a lot (I started writing Envo at0.14.x, then updated to0.15.2and already updated to0.16.0), that way it is within my control to update the parser as needed.
The first issue for me was where to begin, my idea before building this was simply, “I would like to be able to extract key / pair values out of a text file”.
I thought that one way to get started would be to iterate through each character, save them in a buffer until I find an assignment (=), then get the rest of the value until the end of the line, save them and keep working through the file, line by line until we reach the end of the file.
I'll use the following `.env` as an example:
unquoted=Envo
inline_comment=you_value # Inline comment, surprise! 🎉
double_quoted="Envo"
single_quoted='Envo'
multiline="-----BEGIN CERTIFICATE-----
MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEA
-----END CERTIFICATE-----"
mixed_content=hello, she said "see you later" to 'Florencio'.
empty=
white_space=" "
The .env.example is a fairly simple one with quoted and unquoted values, a few mixed, an empty one, an inline comment and a multiline value.
This simple parser reads the file and adds them to a `std.StringHashMap` as key/value pairs:
// src/simple_parser.zig
const std = @import("std");
pub fn main(init: std.process.Init) !void {
const gpa = init.gpa;
const io = init.io;
var arena = std.heap.ArenaAllocator.init(gpa);
defer arena.deinit();
// Read the file's contents:
const file_path = "./.env.example5";
const cwd = std.Io.Dir.cwd();
const max_file_size: usize = 1024 * 1024;
const contents = try cwd.readFileAlloc(io, file_path, arena.allocator(), std.Io.Limit.limited(max_file_size));
var env_values = std.StringHashMap([]const u8).init(arena.allocator());
// We will add to this accumulator and clear it once we form a key or pair.
var bytes_accumulator: std.ArrayList(u8) = .empty;
var key: []const u8 = undefined;
var value: []const u8 = undefined;
defer arena.allocator().free(key);
defer arena.allocator().free(value);
for (contents) |byte| {
switch (byte) {
'=' => {
// Grab key and free bytes:
key = try arena.allocator().dupe(u8, bytes_accumulator.items);
bytes_accumulator.clearAndFree(arena.allocator());
},
'\n' => {
// Grab value and free bytes.
value = try arena.allocator().dupe(u8, bytes_accumulator.items);
try env_values.put(key, value);
bytes_accumulator.clearAndFree(arena.allocator());
},
else => {
// Add the character to the accumulator:
try bytes_accumulator.append(arena.allocator(), byte);
}
}
}
var it = env_values.iterator();
while (it.next()) |entry| {
std.debug.print("{s} => {s}\n", .{ entry.key_ptr.*, entry.value_ptr.* });
}
}
In highlights a few limitations, the multiline is only partially there, the comment is included as part of the value, the space in the key name is part of the name of the key.
There’s a few other limitations as well such as it is not able to parse a file with empty lines at the start or comments in their own line because it expects the = delimiter to be present, escaped quotes and other common cases.
zig run src/simple_parser.zig
single_quoted => 'Envo'
multiline => -----END CERTIFICATE-----"
unquoted => Envo
inline_comment => you_value # Inline comment, surprise! 🎉
double_quoted => "Envo"
white_space => " "
mixed_content => hello, she said "see you later" to 'Florencio'.
empty =>
However, this can be a working parser if the .env file is edited to fit within these constraints and the logic could be further tweaked to actually handle all these cases.
This in itself would probably work for most cases but I decided to look further into how to make the parser sturdier and took it as an opportunity to learn a bit more about how parsing works and how different techniques can work here.
Loading the file contents
First and foremost, and not so relevant to parsing itself, I had to learn how to read a file in Zig and had to decide how large the file can be, allocate a buffer to read the file and keep collecting the contents until I have the full text. A lot of languages hide some of these details in an abstraction but in this case a decision has to be made.
There’s many ways of reading a file and different techniques depending on how long the file is. Typically, .env files are small so I decided to read it in full.
pub fn loadFile(io: std.Io, allocator: Allocator, file_path: []const u8) ![]u8 {
const cwd = std.Io.Dir.cwd();
// To read all the file we need to define the max size for it, pass the path where to look for the file and allocate it to memory.
const max_file_size: usize = 1024 * 1024; // 1mb.
const contents = try cwd.readFileAlloc(io, file_path, allocator, std.Io.Limit.limited(max_file_size));
return contents;
}
While reviewing my code, Loris suggested that setting the sizes to u32 is a good rule of thumb, in his case working with .html files it won’t be larger than 4GBs and that I could do the same here.
I added a loadFile function for convenience and set it to 1mb as I think that’s plenty and I thought if for an edge case where more is needed users can define their own read file methods.
The anatomy of a parser
A parser is a program that reads raw text with no inherent meaning and turns it into structured data the rest of the program can use.
When putting together a parser, there are a few concepts I found I needed to understand.
A lexer scans raw text and classifies each chunk into tokens we can later use for further processing. For example it can tell that = is an EQUALS token, a space is a WHITE_SPACE and a group of characters is a WORD token.
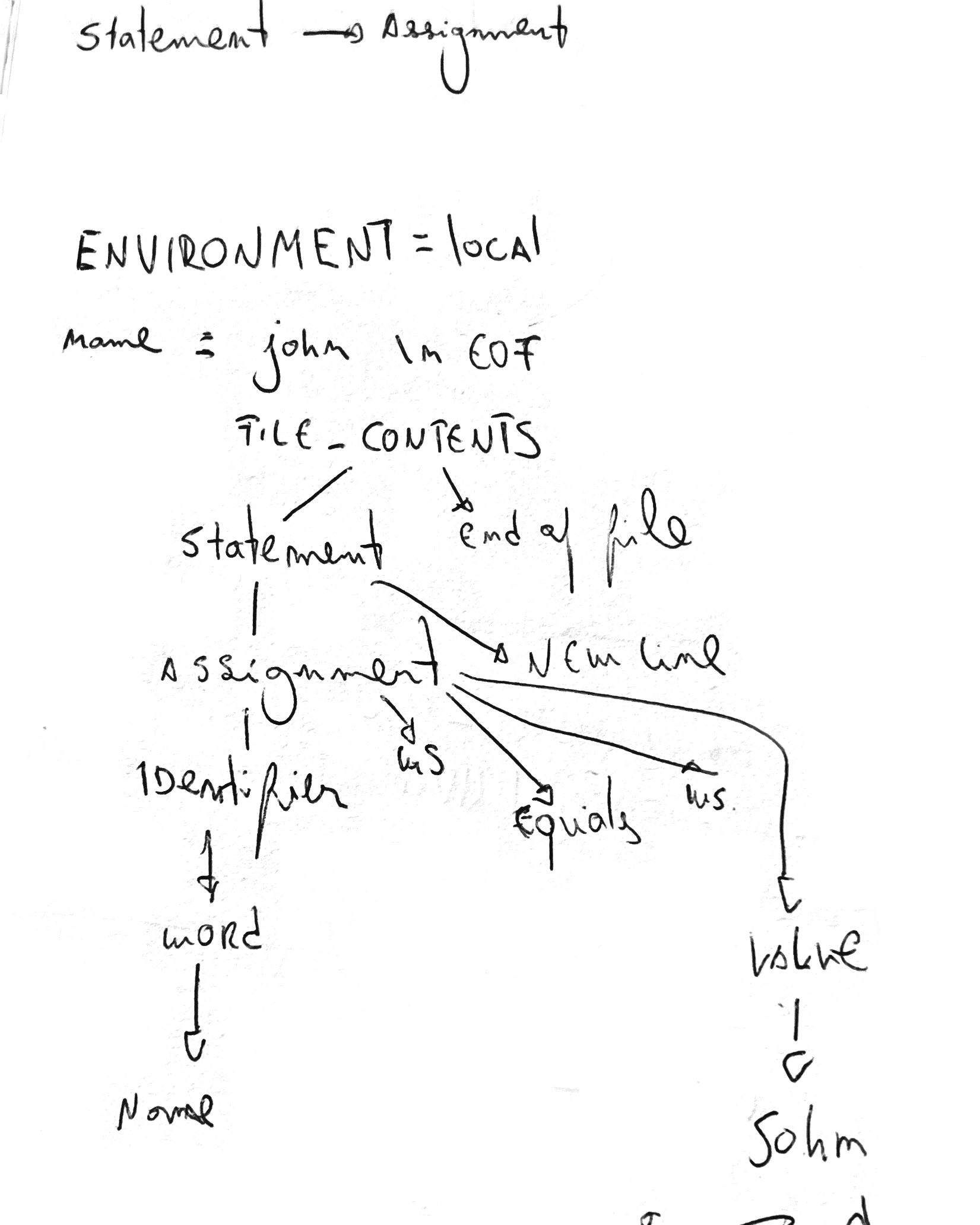
A grammar specifies what a .env file looks like. We can think about it as a rule book we can refer to understand what a .env statement and other parts of the file means depending on the token combination. A grammar is composed of productions, typically defined in Backus–Naur Form (BNF).
Envo's grammar `v1.8`:
<FILE_CONTENTS> ::= NEW_LINE* <STATEMENT>* END_OF_FILE
<STATEMENT> ::= <ASSIGNMENT> WHITE_SPACE* (NEW_LINE+ | END_OF_FILE)
<ASSIGNMENT> ::= <IDENTIFIER> (WHITE_SPACE)* EQUALS (WHITE_SPACE)* <VALUE>
<IDENTIFIER> ::= WORD
<VALUE> ::= <MIXED_CONTENT> | ε
<MIXED_CONTENT> ::= <VALUE_TOKEN> (WHITE_SPACE* <VALUE_TOKEN>)*
<VALUE_TOKEN> ::= WORD | DOUBLE_QUOTED_STRING | SINGLE_QUOTED_STRING
The parser takes the tokens and using the grammar rules returns the structured data. In Envo’s case it generates a tree of nodes and from there we can extract <IDENTIFIER> and <VALUE> nodes and place them in hash map for use in the rest of the program. It’s also an opportunity to stripQuotes for example so that the values are easier to use.
An additional reason to use this approach instead of simply improving the parser I shared earlier is that it gives us more guarantees that it can actually parse the file because we can check whether the grammar has any ambiguity or is missing any gaps.
Parsing strategies
Envo is a recursive descent parser, which performs an LL(1) parse. It’s essentially a label for a predictable kind of top-down parsing.
Earlier in the grammar we can see terminal symbols and non-terminals. Non-terminals need to be expanded and processed until we reach a terminal.
There’s three pieces to this strategy:
- First L — Left-to-right. It reads the tokens in order, start to finish, no backing up.
- Second L — Leftmost derivation. At each step it expands the leftmost unexpanded non-terminal first. In plain terms: it always works on the next thing, top-down, never jumping around.
- The (1) — one token of lookahead. To decide which grammar rule to apply, it’s allowed to peek at exactly one upcoming token. One glance, then it makes a choice.
This strategy in particular allows the parser to never guess or backtrack to structure the data. At every decision point, the single next token tells it unambiguously which rule to take.
One example is the parseValue function. A WORD or quoted string means “go parse mixed content” anything else means “empty value”.
It works by using FIRST sets. A FIRST set is “which tokens can legally start this rule.” LL(1) works when, at every branch point, the alternatives have non-overlapping FIRST sets, so one token of lookahead always disambiguates.
For example, <MIXED_CONTENT> begins with a <VALUE_TOKEN>, and a <VALUE_TOKEN> is a WORD, a DOUBLE_QUOTED_STRING, or a SINGLE_QUOTED_STRING. Like so:
FIRST(<MIXED_CONTENT>) = { WORD, DOUBLE_QUOTED_STRING, SINGLE_QUOTED_STRING }
If <MIXED_CONTENT> can start with WORD and any other branch could also start with WORD, then seeing a WORD wouldn’t tell the parser which way to go and one token would be ambiguous, and LL(1) would be impossible without more lookahead.
What if a parser did look ahead more than one token or what if it took a bottom-up approach? There are other approaches too, I am not an expert but we can outline them as follows just for comparison:
- LL(k): same idea, but k tokens of lookahead instead of one.
- LR / LALR (bottom-up, shift-reduce): Instead of predicting top-down which rule you’re entering, it accumulates tokens on a stack and recognizes completed rules once it has seen enough (reduces bottom-up). Handles grammars LL can’t but the grammar is not clearly shown in the code.
- PEG / packrat - To me it seems like it is a way of describing a grammar where, at every choice, the parser tries the options in the order you listed them and takes the first one that works and if an option leads to a dead end, it simply backs up and tries the next. It might also remember a result that worked before.
- General parsers (Earley, GLR, Marpa): These types of parsers can usually handle any grammar, including ambiguous ones. The trade is speed and complexity, and I haven’t look deeply into these because the
.envparser didn’t seem to benefit from this approach.
As a first parser it looked like aiming for LL(1) was best since it gives certainty, it doesn’t backtrack and there’s not more than one lookahead token to worry about.
The two strategies
During the development of Envo I wanted to explore more than one implementation and decided to do two, recursive descent using the stack and using the heap.
I ended up with recursive_descent.zig and iterative.zig which are actually both recursive descent in the sense that they take a top-down approach with the same grammar and the test files generate the same ASTs from both, but they differ in the mechanism used to get there.
Recursive descent (native recursion):
- Each non-terminal is a function and sub-rules are function calls. e.g.
parseAssignmentcallsparseIdentifierthenparseValue. - Uses the language’s call stack. The runtime tracks where to resume after each call returns which requires little book keeping on where we’re at.
- Reads top-to-bottom like the grammar and we can practically map the rules line-for-line onto the BNF.
- The downside which I argue it’s unlikely to hit with an
.envfile is that call depth is limited by the stack size and deeply nested input can result in overflow.
Iterative (explicit stack):
- Same descent but the stack is built by hand. There’s a
CallStackofStackFrames on the heap, awhileloop dispatching the top frame to its handler. pushreplaces the function call,popreplaces the return, andstepreplaces the return address. A manual record of where each frame resumes after its children finish is kept.- I guess the cost is verbosity. It’s not so easy to map the grammar to the logic.
- An added benefit is the heap tolerates far deeper input without overflowing, but it’s worth pointing out that this is unlikely to happen with an
.envnode tree.
I have also added some tests to the lexer and the parser to confirm that various values are supported and handled correctly.
How to use it in a project
Essentially, there’s three steps as of the time of writing. Read the .env’s contents, parse them and access them:
const std = @import("std");
const envo = @import("envo");
pub fn main(init: std.process.Init) !void {
const gpa = init.gpa;
const io = init.io;
const base_allocator = gpa;
const env_contents = try envo.loadFile(io, base_allocator, "./.env");
defer base_allocator.free(env_contents);
var parse_arena = std.heap.ArenaAllocator.init(base_allocator);
defer parse_arena.deinit();
const env_data = try envo.parse(parse_arena.allocator(), .RECURSIVE_DESCENT, env_contents);
const app_name = env_data.get("APP_NAME").?;
const app_port = env_data.get("APP_PORT").?;
const app_env = env_data.get("APP_ENV").?;
}
Further Improvements
There’s a few aspects in particular that I would like to add and improve on.
One aspect I would like to see improve is to remove the requirement for users pick a parsing strategy as they likely just would like to extract the values and get on with their day. I’d like to go from the current state to something like the following:
// From this:
const env_data = try envo.parse(parse_arena.allocator(), .RECURSIVE_DESCENT, env_contents);
// To this:
const env_data = try envo.parse(parse_arena.allocator(), env_contents);
A bug fix is the The stripQuotes one, I would like to add tests to it to make sure values like "a" and "b" don’t break. Currently, it will return a" and "b and that needs fixing.stripQuotes issue has been addressed.
As a lower priority one I would like to experiment with having interpolation so we can do something like this, for instance:
APP_NAME=Envo
WELCOME_MESSAGE="This is ${APP_NAME}, a `.env` parser for Zig."
However, this seems more like a nice to have and I don’t find that featured being used a lot in general with other .env parsers in my experience.
Further more, Loris Cro was kind enough to have a quick look at my project which I am very grateful for and he has provided very valuable feedback which I hope to apply some of at some point:
- Implement a proper build step for tests. Right now tests are scoped to their own files and I have to run then individually. [1]
- Change enum casing from upper snake cased to snake case, that is the Zig convention. [2]
- Limit every
usizetou32s. [3] - It might not be necessary to use an
ArrayListto keep tokens around and perhaps instead of keeping track of a line and column counts, compute it from byte offset instead. [4] - Learn to use labeled switches to leverage for loops that have
switchnested in them as a way of avoidingforandwhilealtogether (a Duff’s Device). [5]
It was really interesting to attempt at creating something like this, it started by extracting key/value pairs from an .env file to realising there’s actually a few more considerations that led me to develop a grammar with a complete lexer and parser that I can use in my own projects.
References
Blunden, R. (2021, June 16). The triumph and tragedy of .env files. Doppler. https://www.doppler.com/blog/the-triumph-and-tragedy-of-env-files
Cro, L. (2026, June 10). Zig livecoding: Ziggin [Video]. YouTube. https://www.youtube.com/live/gzN022TiORQ
csalmeida. (2025). Envo [Computer software]. GitHub. https://github.com/csalmeida/envo
The .env file: A complete guide to environment variables. (2026). env.dev. https://env.dev/guides/dotenv
Free Software Foundation. (n.d.). Wisent parser: Iterative style. GNU Emacs Manual. https://www.gnu.org/software/emacs/manual/html_node/wisent/Iterative-style.html
Grune, D., & Jacobs, C. J. H. (2008). Parsing techniques: A practical guide (2nd ed.). Springer. https://link.springer.com/book/10.1007/978-0-387-68954-8
Keepers, B. (2012). dotenv: A Ruby gem to load environment variables from
.env[Computer software]. GitHub. https://github.com/bkeepers/dotenv
Kegler, J. (2019). Marpa, a practical general parser: The recognizer (arXiv:1910.08129). arXiv. https://arxiv.org/abs/1910.08129
Motte, S. (2013). dotenv [Computer software]. GitHub. https://github.com/motdotla/dotenv
The Rust Project Developers. (n.d.). Rules for determining width. unicode-width crate documentation. https://docs.rs/unicode-width/latest/unicode_width/#rules-for-determining-width
Schlinkert, J. (2025). env: A specification for the .env file format [Specification]. GitHub. https://github.com/env-lang/env/blob/main/env.md
Super User. (2019). Is there a text editor which displays column numbers and/or displays text in a grid? [Online forum post]. https://superuser.com/questions/1407714
Tratt, L. (2020). Which parsing approach? https://tratt.net/laurie/blog/2020/which_parsing_approach.html
Williams, C. (2022). On recursive descent and Pratt parsing. https://www.chidiwilliams.com/posts/on-recursive-descent-and-pratt-parsing
Wiggins, A. (2017). The twelve-factor app: Config. https://12factor.net/config